In my role as a Consulting SE for RoundTower, I often perform assessments of our customers' storage environments. When those customers use NetApp storage and it's under support, I have a wealth of tools at hand via the ActiveIQ portal to help understand how they use they manage their storage systems and the data they hold. Unfortunately, I often find myself working with customers that I don't have direct partner-level access to their systems via the ActiveIQ portal or the customer has perhaps held some systems well past their expected service life and they're running with 3rd party hardware replacement support only. Even when I do have ActiveIQ data, I generally want to look at the in depth, detail of how the system is configured. In other words I will dig into the raw autosupport data at some depth to understand the environment.
I will: request a copy of the full weekly autosupport payload file from
all of their NetApp nodes. What this means is that I want the body.7z file
that's attached to the weekly autosupport email those nodes generate. When you
unpack one of these via mkdir netapp-node4 && cd netapp-node4 && 7z
../body.yz~ you'll find something that looks like this:
FVFY612RHV2J:netapp-node4 sharney$ tree
.
├── ACP-IBACP-LIST-ALL.txt
├── ACP-STATS.txt
├── AGGR-MEDIA-SCRUB-STATUS.txt
├── AGGR-SCRUB-STATUS.txt
├── AGGR-STATUS-R.txt
├── AGGR-STATUS-S.txt
├── AGGR-STATUS-V.txt
├── BOOT-DEVICE-INFO.txt
├── CHECKSUM-STATUS.txt
├── CLUSTER-INFO.xml
(snip)
├── vvolTable.xml
├── wafl-zki-show-top.txt
├── web-crypto.xml
├── web_server.xml
└── zapi-kern-zapi-stats.xml
0 directories, 486 files
FVFY612RHV2J:netap-node4 sharney$Whoa! 486 files and most of it xml. My eyes are going to burn trying to read that. I thought maybe this is a chance to use and learn a little Python. If I can get the content of those xml files into a spreadsheet, I can create some tables, do some filtering, do a little math and start understanding a lot about the system and start building out my assessment reports. In my first go of this I managed to figure out the general layout of xml files I was interested in and extract their values into csv format. Once I had csv files I could manually put together my spreadsheet.
This was a pretty good start but I still spent a lot of time just building the sheet and not enough time analyzing the data. I came across a very useful Python module, XlsxWriter . With it I can take it one step further and produce a single spreadsheet with tables already built, autofiltering available, and summaries applied where those are valuable.
In one quick commandline invocation I can produce a spreadsheet that parses out the xml files into something I can start using and analyzing right away:
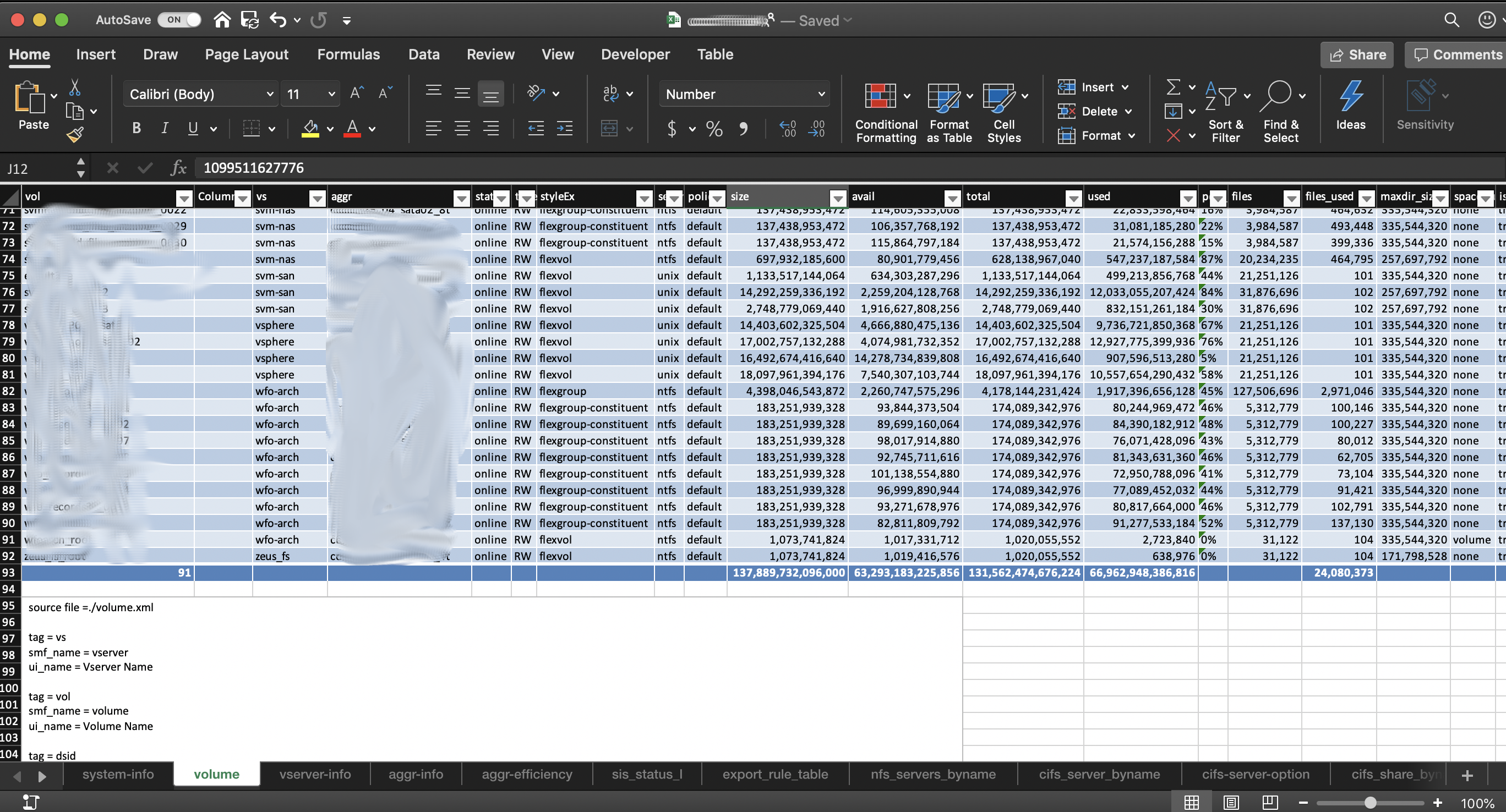
This only takes a look at a single node at a time and some of the XML data in
the body.7z maps to the entire ONTAP cluster scope while other items –
volumes, luns, etc – are node-specific. In this iteration I still need to
generate multiple sheets and then do a little cutting and pasting to get a
comprehensive cluster-wide view of all the content. It shouldn't take too
much work to recursively walk a tee of directories with the multiple node asup
data and produce a single spreadsheet in one go.
I've done a bit of Python here and there but to really learn a language you need to find an itch to scratch and build something useful. This saves me a ton of time now that it's built. I learned a lot of Python along the way and I can use that to build parsers for other systems. The github repo for this may be found here if you're interested.